
A friend of mine told me about Ollama today, a text-favouring local solution for running LLMs and I gave it a go. It was easier than I expected!
First you download and install Ollama: https://ollama.com/
Once installed, you run it, and it sits as a background service. If on Windows it will add a system startup item, which you can disable from Task Manager.
Second, you need to get the name of a model. Once in the list, click into one to then get its own page, which will have a drop-down menu to choose the model size. Match this size to be just under the max VRAM of your GPU (for my 3070 RTX it was 8GB or less).
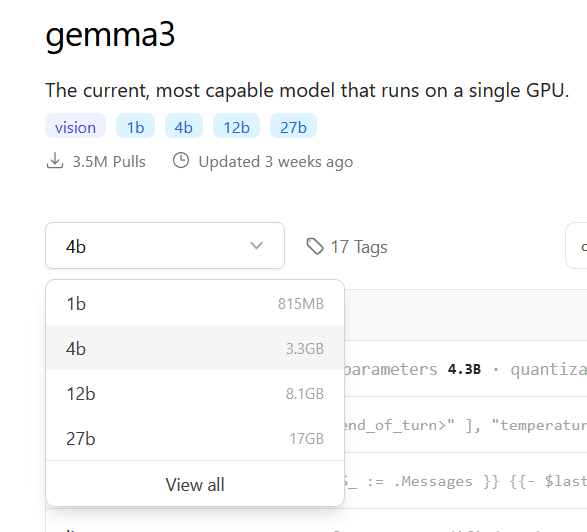
I can’t fit the 12b into memory, so I went with a 4b. All you need to do is take note of two things, the model name “gemma3” and the numbered size “4b”. We’ll reference that in the next step.
Run Terminal (Windows 11) or CMD (Windows 11 or prior) and the “ollama” executable should be in your execution path. If not, add it to your operating system.
Run ollama and tell it which model and size to run. You won’t have this yet, so it will auto-download it and run right after (model identifier is model name, colon, and its size):
>ollama run gemma3:4b
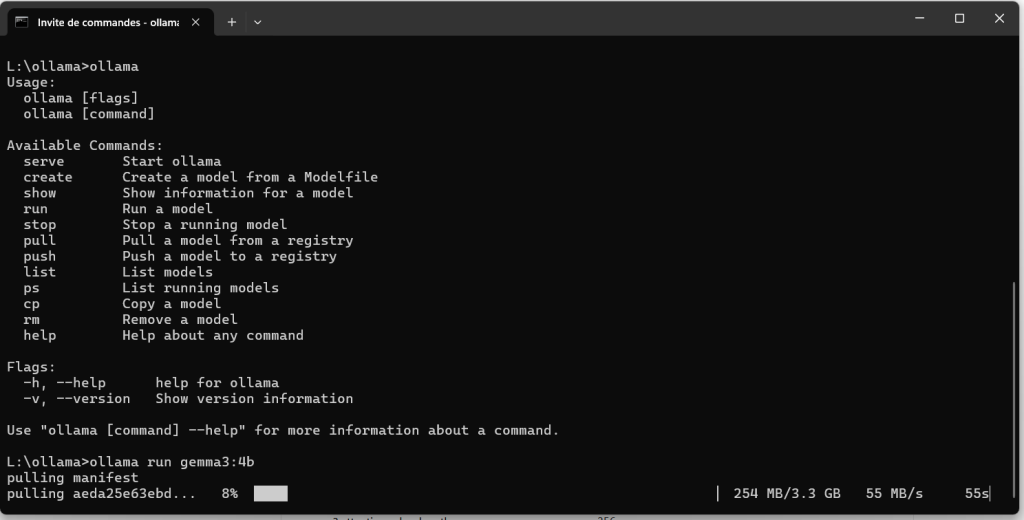
One main file will download along with some smaller ones. You know it’s downloaded and running properly when the next thing you see is the prompt:
>>> Send a message (/? for help)If you don’t get this because the model size you chose was too big, you’ll get errors. I tried a model that was too big on a Mac after some success in Windows, and got an error. I was hoping its 16gb unified Apple Silicon memory would allow for a larger model compared to my PC’s 8gb VRAM, and nope! So I had to choose a smaller model, as I did on the PC:
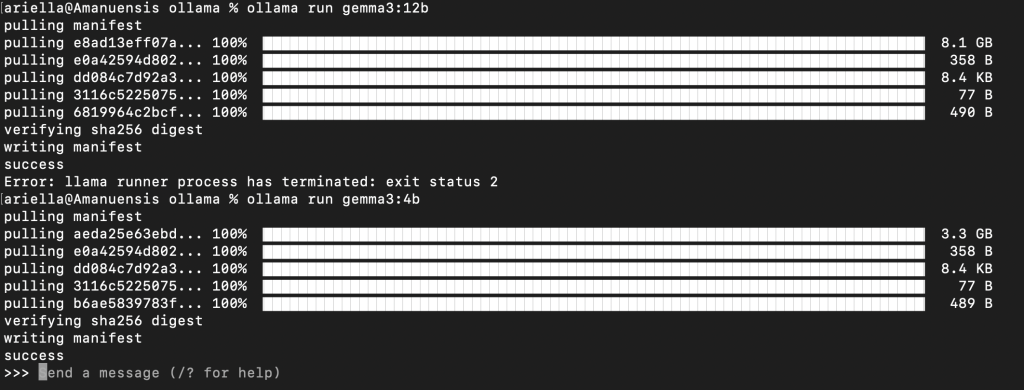
Ask it a question! Enjoy. 🙂
If you download a model you don’t like and want to delete it, get its name from the list of models if you don’t remember it:
> ollama list

And then remove it by typing a command like this:
> ollama rm gemma3:4b